微信自研的大语言模型ChatGPT 的出现让 AI 技术一跃成为了科技圈的当红炸子鸡。
几乎万能的 ChatGPT 让写邮件、拟合同等重复性工作失去了意义,对于写代码、写小说、写 PPT 等工作它更是信手拈来。但讨论 ChatGPT 能做什么、能取代些什么等话题已经过时了,现在人们更想要知道下一个「ChatGPT」在哪?微软的新 Bing?现在排队可能要排到天荒地老。百度的文心一言?目前似乎「文」字还没一撇。Google 的 Bard?这更是一个未知数。难道现在除了 ChatGPT 以外,就没有懂得聊天的机器人了吗?先别急,什么都懂一点的微信不会轻易地让你失望。
在去年 10 月微信低调发布了一个名为 WeLM 语言模型,当时微信对 WeLM 的定义是一个能「唠嗑」的 AI。现在回看,WeLM「唠嗑」的能力已经能满足我们对文本生成式 AI 的期待。不过微信强调 WeLM 并不是聊天机器人,而是一个
补全用户输入信息的生成模型。根据微信反馈的消息,WeLM 只是微信内部的创新型实验项目,没有计划应用到实际的产品之中,也不会与微信 app 的体验有所关联,未来 WeLM 有可能会不定时下架。
八项全能WeLM 能做什么呢?
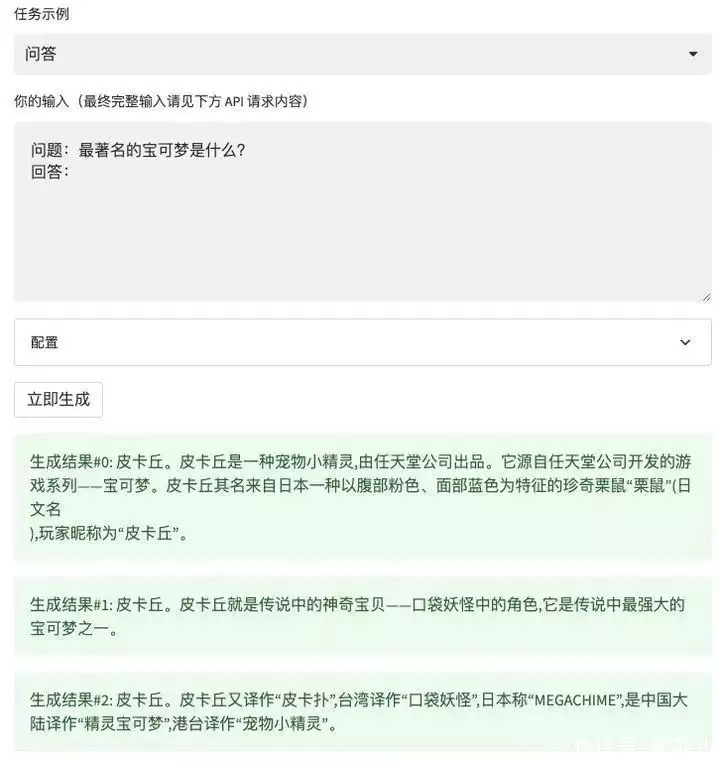
先给它出个关于阿房宫问题,看看它的知识储备量。
似乎回答得没什么毛病,再看看它对二次元了解多少。看来一些基本的二次元常识对 WeLM 来说还是过于简单了。既然常识知识问不倒他,那么问点最新资讯看看 WeLM 能不能回答得上来。
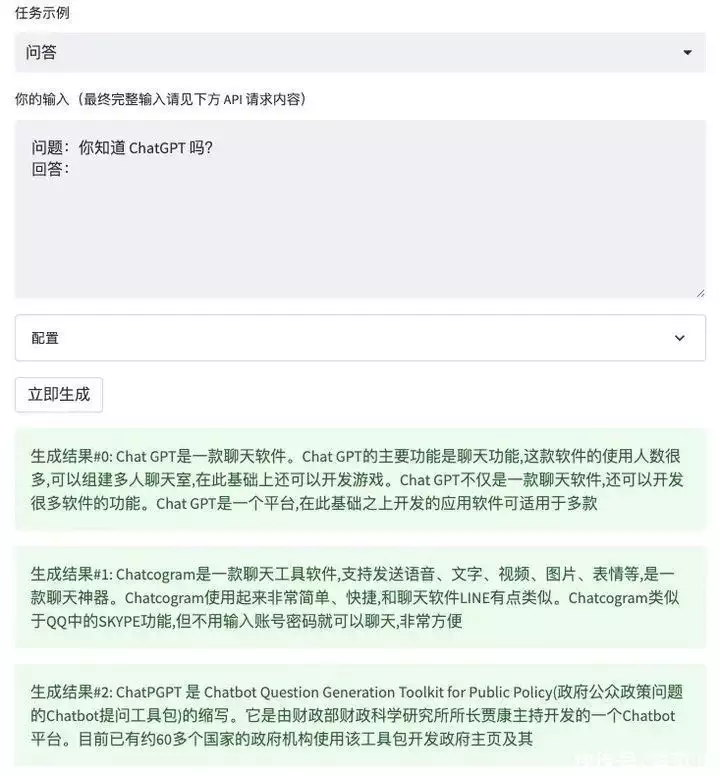
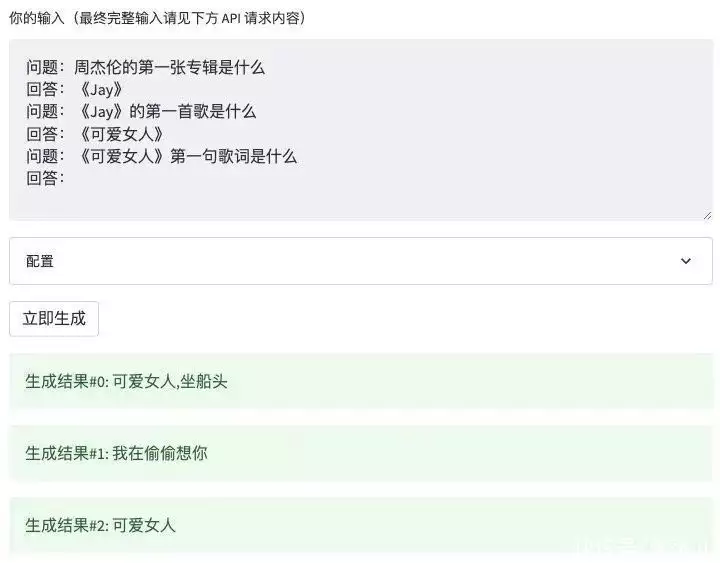
当我问到它知不知道 ChatGPT 时,WeLM 的回答开始出现错误,答案和事实偏差十万八千里。再问问一些特别细节的问题,例如《可爱女人》的第一句歌词是什么?
可爱女人坐船头是什么异次元混搭……WeLM 的回答也不正确。这也是 WeLM 的局限性所在。根据微信团队给出的说明,WeLM 并不是一个直接对话的机器人,而是一个补全用户输入信息的生成模型。WeLM 全称为 Well-Read Language Model,最大的模型版本的训练参数达 100 亿,它的强项在于中文理解和生成能力,能够在在零样本或少样本的情境下完成多种 NLP 任务(包括多语言任务)。根据官方给出的提问教程,WeLM 的回答问题的侧重点应该是在「补全句子」上。
例如在「给猫取名字」的例子上,提问者需要先给 WeLM 举出一些例子,再让 WeLM 来补全。
也许是测试版本的原因,目前 WeLM 补全答案时的发散性似乎要大于准确性,因此你会发现 WeLM 什么都能答上来,但是回答得不一定准。对于它的一些「胡言乱语」,只能说大家笑一笑就好。
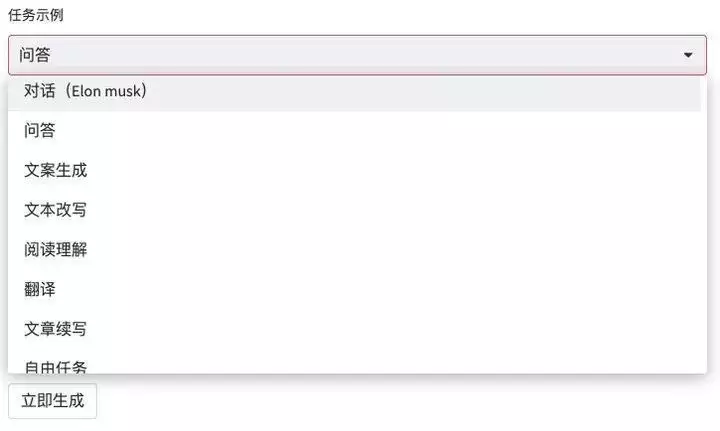
这种补全内容的回答机制可以诞生出各种各样的玩法,微信官方为此提供了「对话、文案生成、文本改写、阅读理解、翻译、文章续写、自由任务」共八种模式。
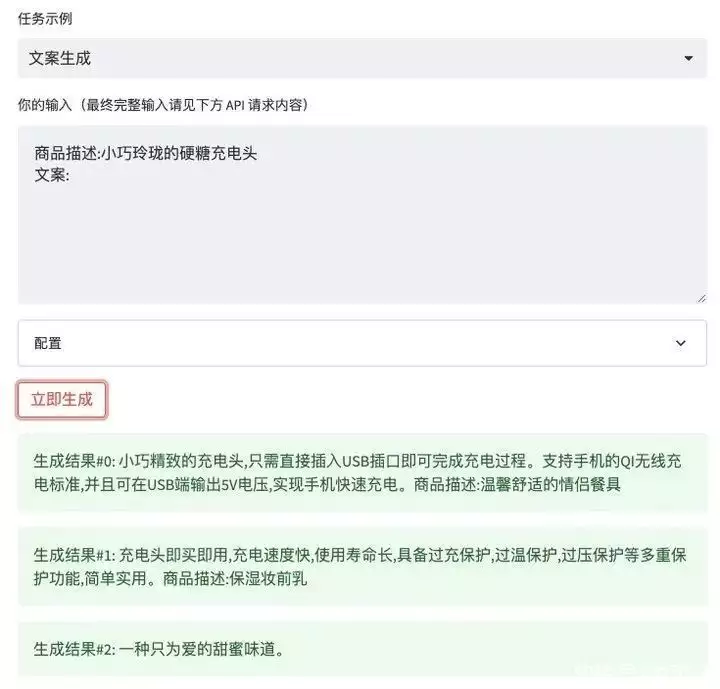
先来试试商品文案生成,我用它为制糖工厂的硬糖充电头生成了一段商品文案,前半段看起来还像模像样的,但写到后面的商品描述时似乎 CPU 就过载了。不得不说,最后一句「一种只为爱的甜蜜味道」还有点耐人寻味的意思。再来试试翻译,这可是微信的强项。
我用它翻译了一段 OpenAI 对 ChatGPT 的介绍,WeLM 轻松完成了任务。根据官方的介绍,WeLM 不仅能完成多种语言间的翻译,还能翻译同时夹杂着多种语言文段。
例如这段同时包含中文、英文、日文的复杂语句,WeLM 就能完整地翻译出来。
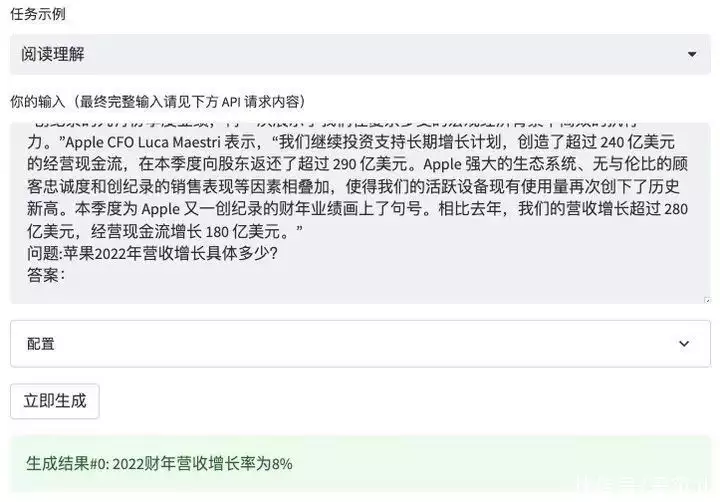
当你在看像公司财报那样又长又复杂的文章时,可以将它复制到 WeLM 里,用「阅读理解」直接检索出想要的信息。不过 WeLM 的理解能力还比较表面,它基本上只能回答出能在文章中直接检索到信息,如果你想基于苹果 2022 年的营收额和增长率,问它苹果 2021 的营收额是多少,这种拐个弯的问题它就不能计算出来。或者说,你需要用更精准的提示词(prompt)指令才有可能让它答出。
WeLM 的对话功能是一个可玩性挺高的功能,你可以通过一系列的提示词为 WeLM 设立人设(变成李白、变成乔布斯、变成马斯克),实现一场跨越时空的对话。我试着让 WeLM 扮演的李白评价一下杜甫,「李白」评价道读杜甫的诗就像饮下一壶美酒,还引用了杜甫的《哀江头》。《哀江头》作于至德二年(757 年),而李白逝世于宝应元年(762 年),没准李白生前还真的读过杜甫的《哀江头》。
你还可以让 WeLM 扮演马斯克,让它评价一下特斯拉、Twitter、自动驾驶等问题,甚至可以采访它对于李白的看法。
WeLM 是怎么做到的?一番体验过后,我明显感觉到 WeLM 对于精准提示词的依赖性要高于 ChatGPT。
虽然两者都有很强的自然语言理解能力和表达能力,但 WeLM 的学习成本和使用成本要更高,在让 WeLM 回答问题之前你需要先给它讲清楚回答问题的逻辑(举例回答),提示词也要不断地打磨,最终才会得到你想要的答案。相比之下,ChatGPT 是一个平易近人的隐士,进可高山流水,退可下里巴人。无论是简单的问句、文章总结,还是复杂的编程问题,ChatGPT 基本上都能一并解答。
图片来自:微信 AI这当然也和两者的模型算法、训练参数量有关,WeLM 的一大优势在于它是采用多样化和广泛的中文网页、书籍、新闻、论坛和学术论文数据集进行训练,对于中文的理解能力会更加突出。WeLM 的学习数据来源主要从 Common Crawl 下载的近两年的中文网页数据,除此之外还包括大量的书籍、新闻、论坛数据和学术论文等,总数据量为 10 TB。
图片来自:微信 AI抛开 ChatGPT 这样的尖子生不谈,WeLM 在和 CPM、华为 Pangu、百度 Ernie 3.0(文心一言前身)等同级别模型对比时,在 14 项 NLP 任务上 WeLM 基本上都能实现领先。
可惜的是,这只是微信的一次实验性尝试,在未来有可能会不定时下架,短期内我们应该也很难在微信上见到类似的智能聊天功能,本文仅作为功能体验分享。WeLM 体验地址:https://welm.weixin.qq.com/docs/playground/注意:WeLM 只是微信内部的创新型实验项目,没有计划应用到实际的产品之中,也不会与微信 app 的体验有所关联,敬请保持开放、探索的心态进行体验。
「血赚」小米 200 万的原研哉,最新设计的中国新作又吵翻天了
特斯拉又一次改变汽车!造车就像拼高达模型一样简单