
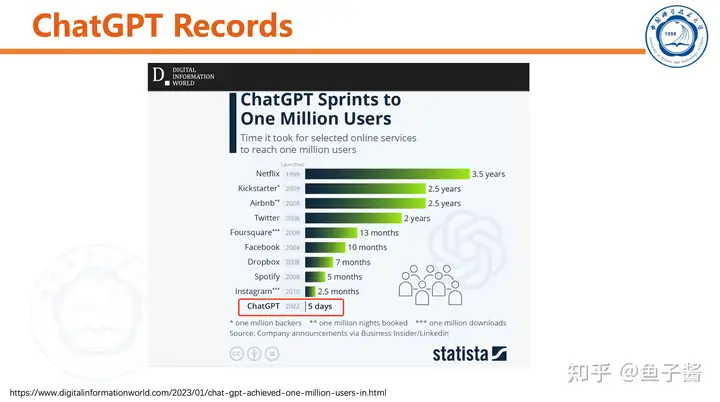
ChatGPT自从2022年底发布以来引起了很大反响,子弹已经飞了两个月了,今天重新整理一下ChatGPT以及个人的一些理解。
TL;DR: ChatGPT的内核是InstructGPT[1]。随着language model(LM)越做越大,InstructGPT的作者们发现这些LMs其实经常和用户的意图不完全一致/对齐,这引发作者们的思考:如何得到能与用户意图更一致的LM?于是InstructGPT横空出世,其目标是“Align language models to humans”,具体的对齐方法采用Reinforcement Learning from Human Feedback(RLHF)[2]。简单说就是在训练LM时要“human in the loop”,用人类的示例/评价/比较等反馈信号调整LM,让LM输出的结果往人类意图方向靠拢。
个人ChatGPT体验报告
ChatGPT在哪些地方帮到我了?
有些中文文档需要很官方的文书表达(比如基金申请书),通过巧妙的提问可以让ChatGPT输出很多思路甚至有些可以直接拿来用;帮助我快速了解一个大的领域,虽然看不太准,但是也提供了一点借鉴。ChatGPT技术上还存在哪些缺陷?
ChatGPT经常一本正经地胡说八道;ChatGPT经常很啰嗦;ChatGPT给出的信息我经常需要用Google double check;ChatGPT每次输出的结果“不一致”(本质原因是因为它是概率模型,每次采样的结果都不一样)。Background


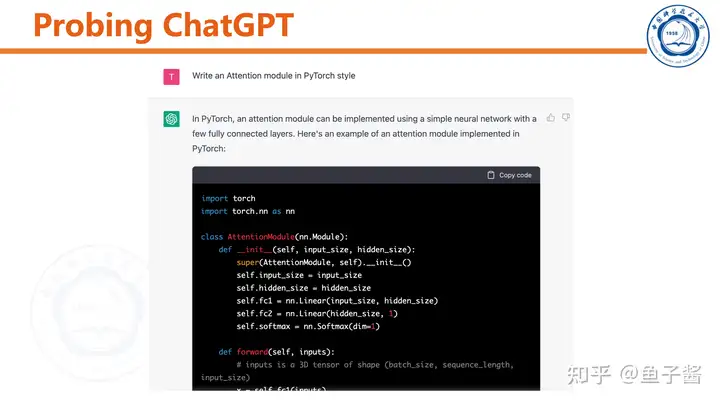
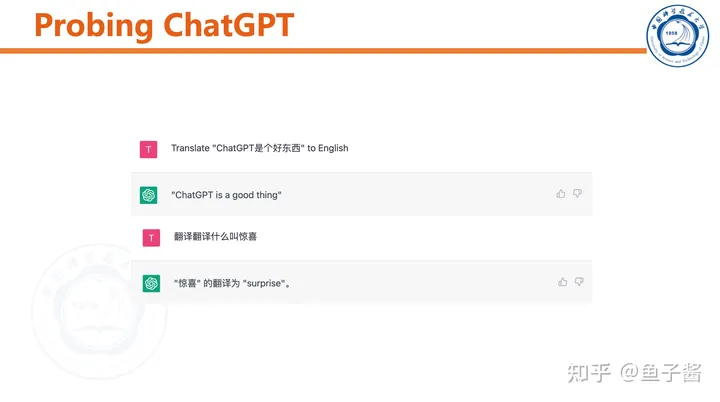
我首先对ChatGPT做了简单的测试,直观感受一下。
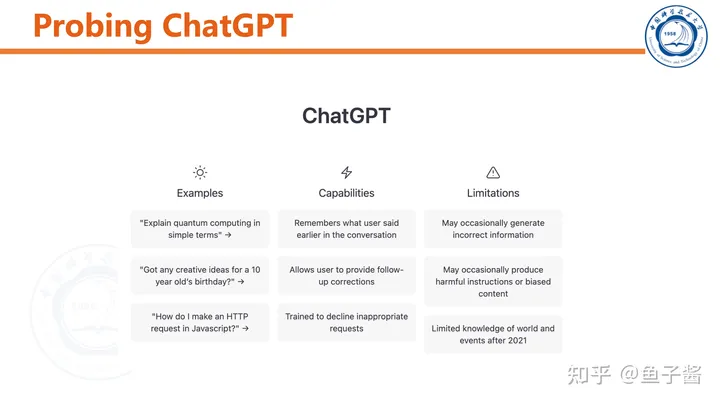
ChatGPT可以和用户“chat”,能根据聊天历史调整输出。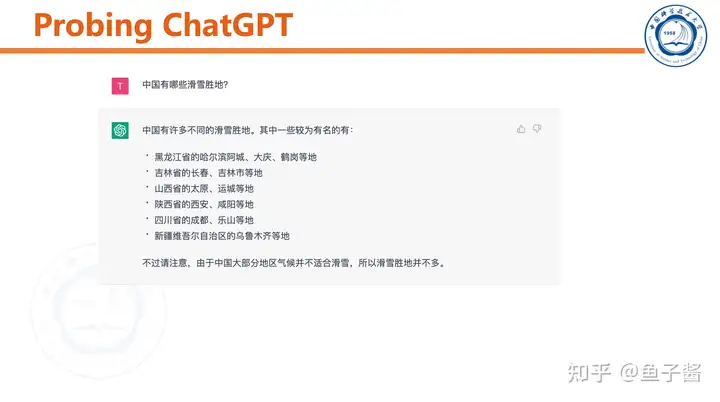


InstructGPT
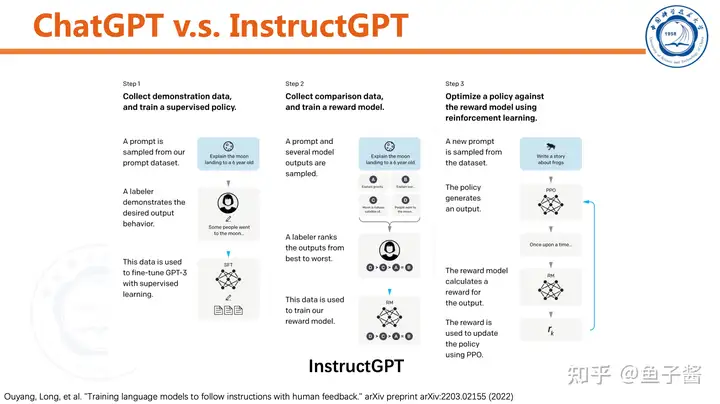
对比一下ChatGPT和InstructGPT,方法几乎一模一样。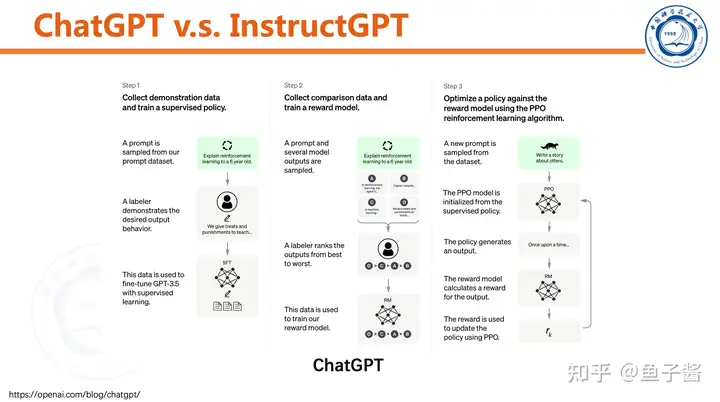


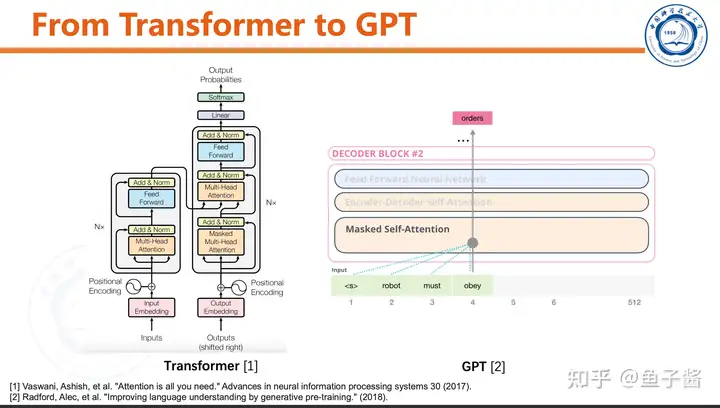
这里展开一下GPT模型的介绍,关键词:Transformer Decoder,生成式,自回归,因果掩码和概率模型。


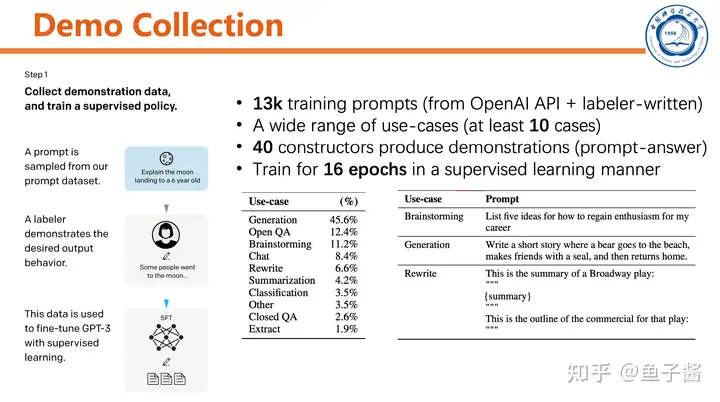
言归正传,对于InstructGPT的第一步:采集人类标注的demo,监督式finetune pretrained GPT。

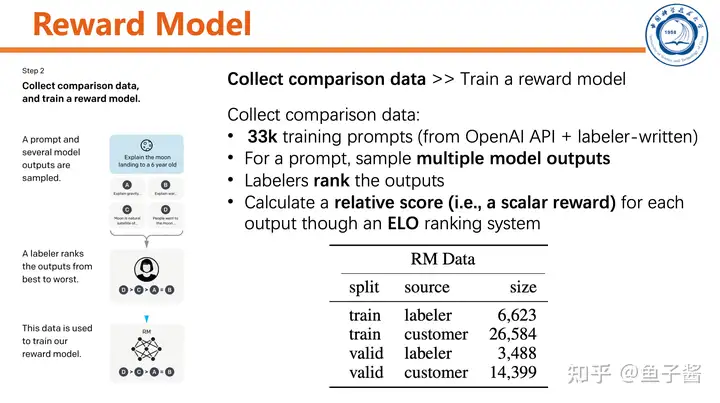
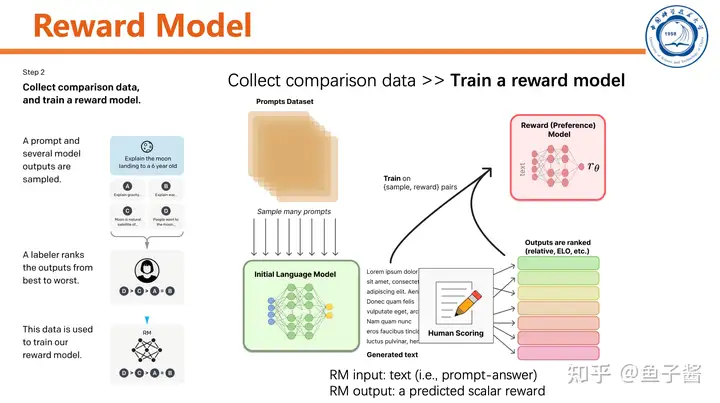
第二步,训练reward model。
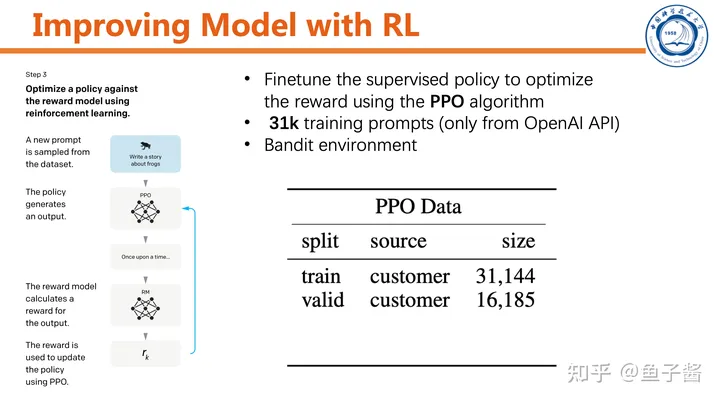
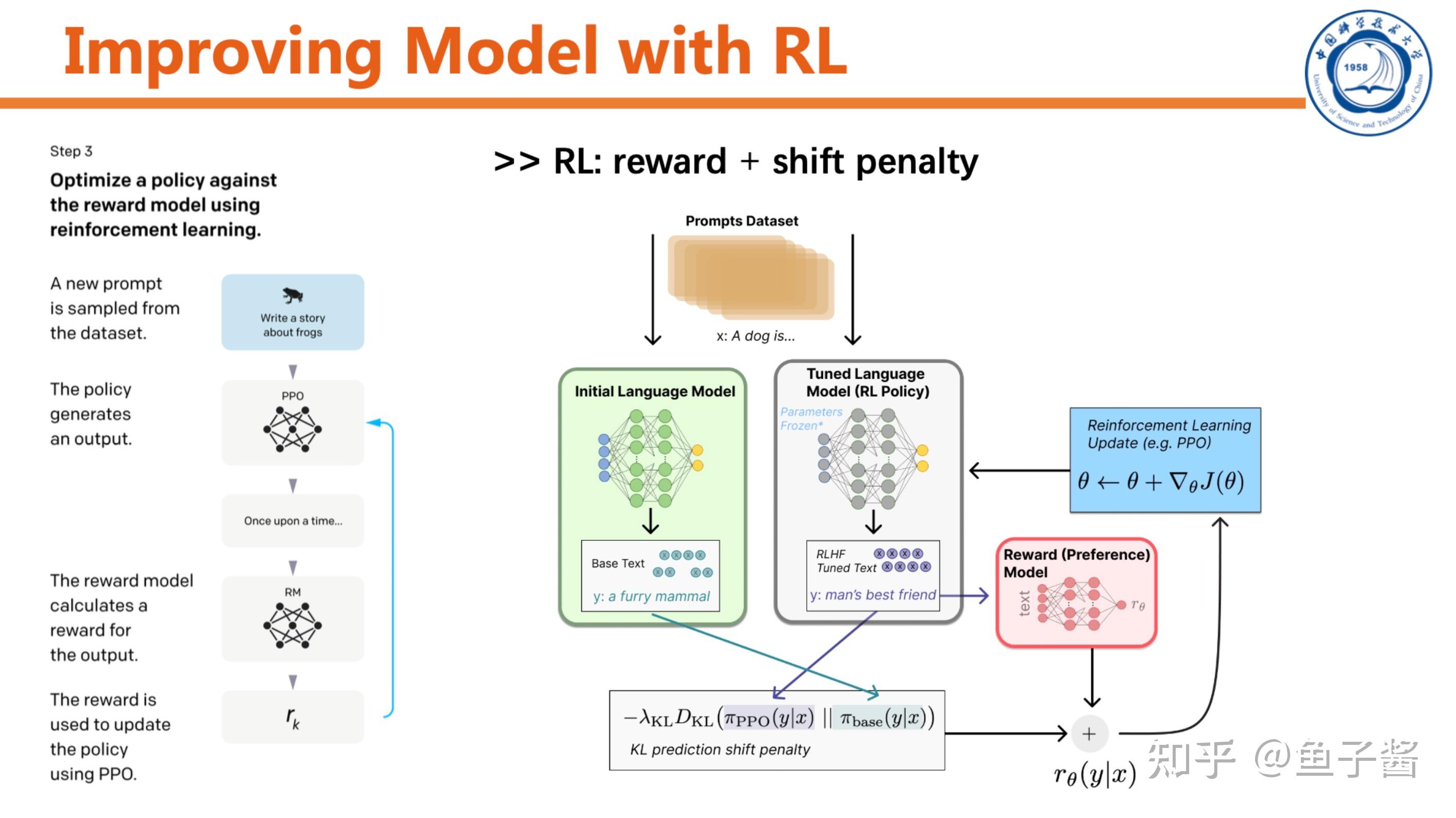
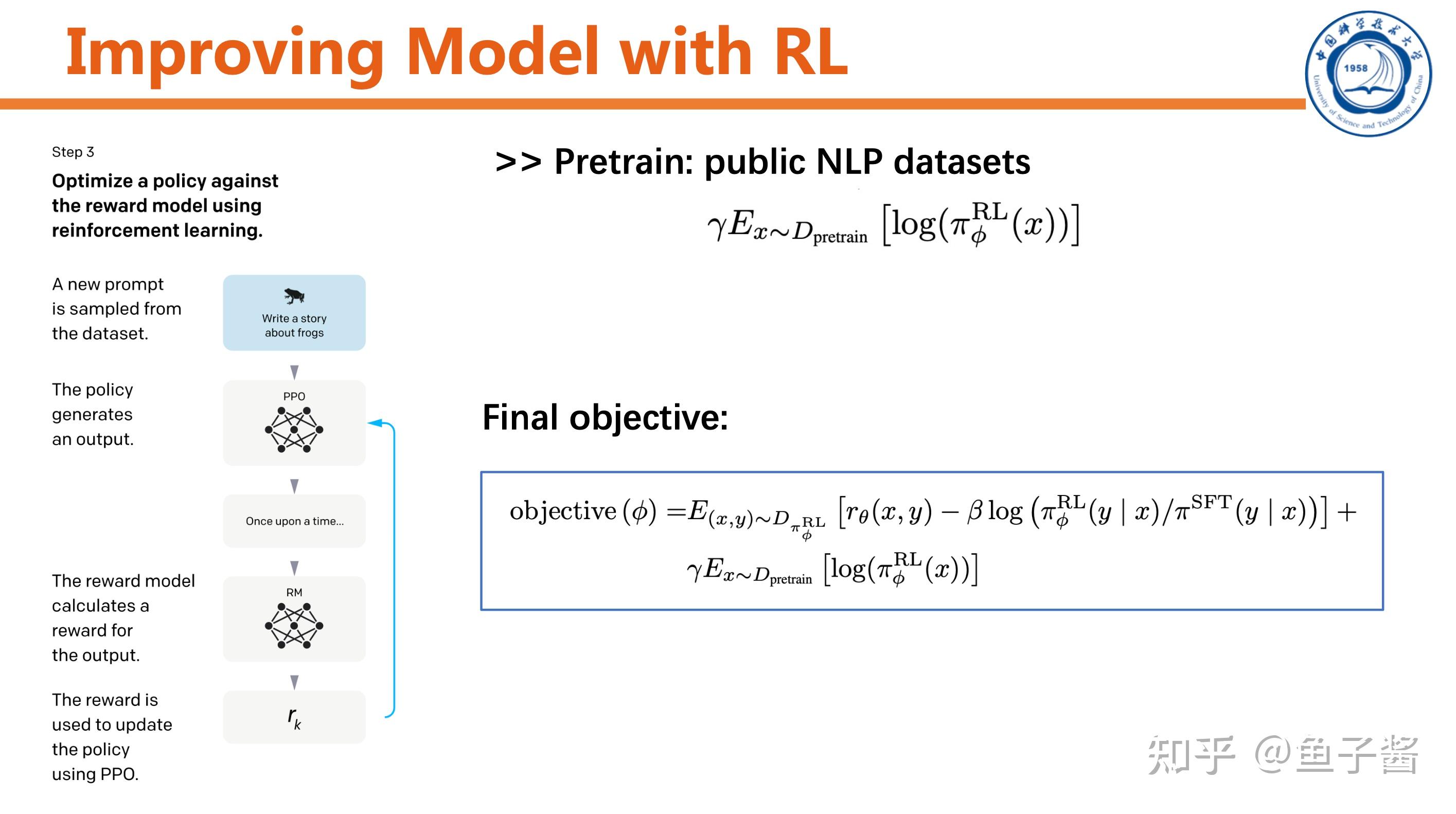
最后一步,用RL提升SFT model。
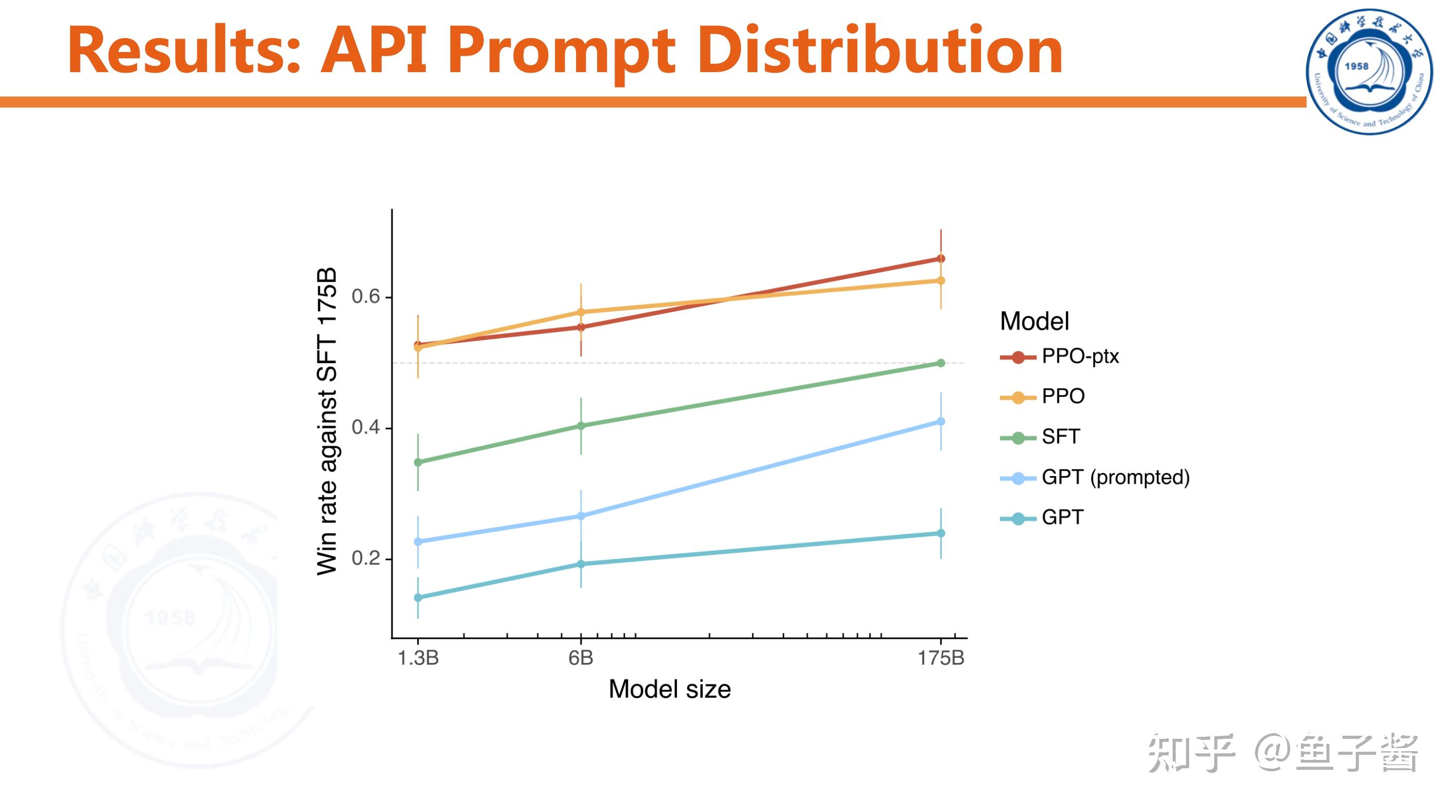
Experiment

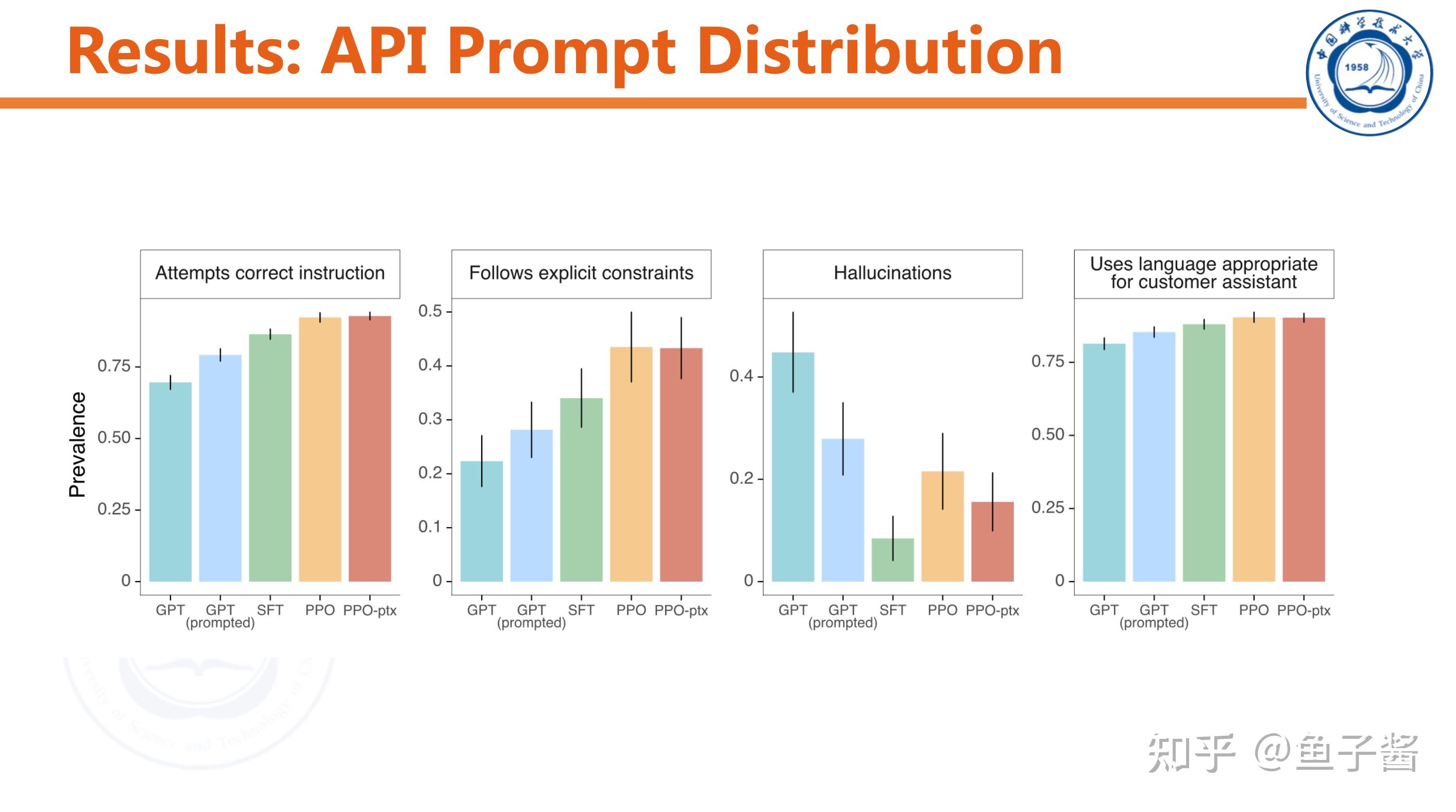

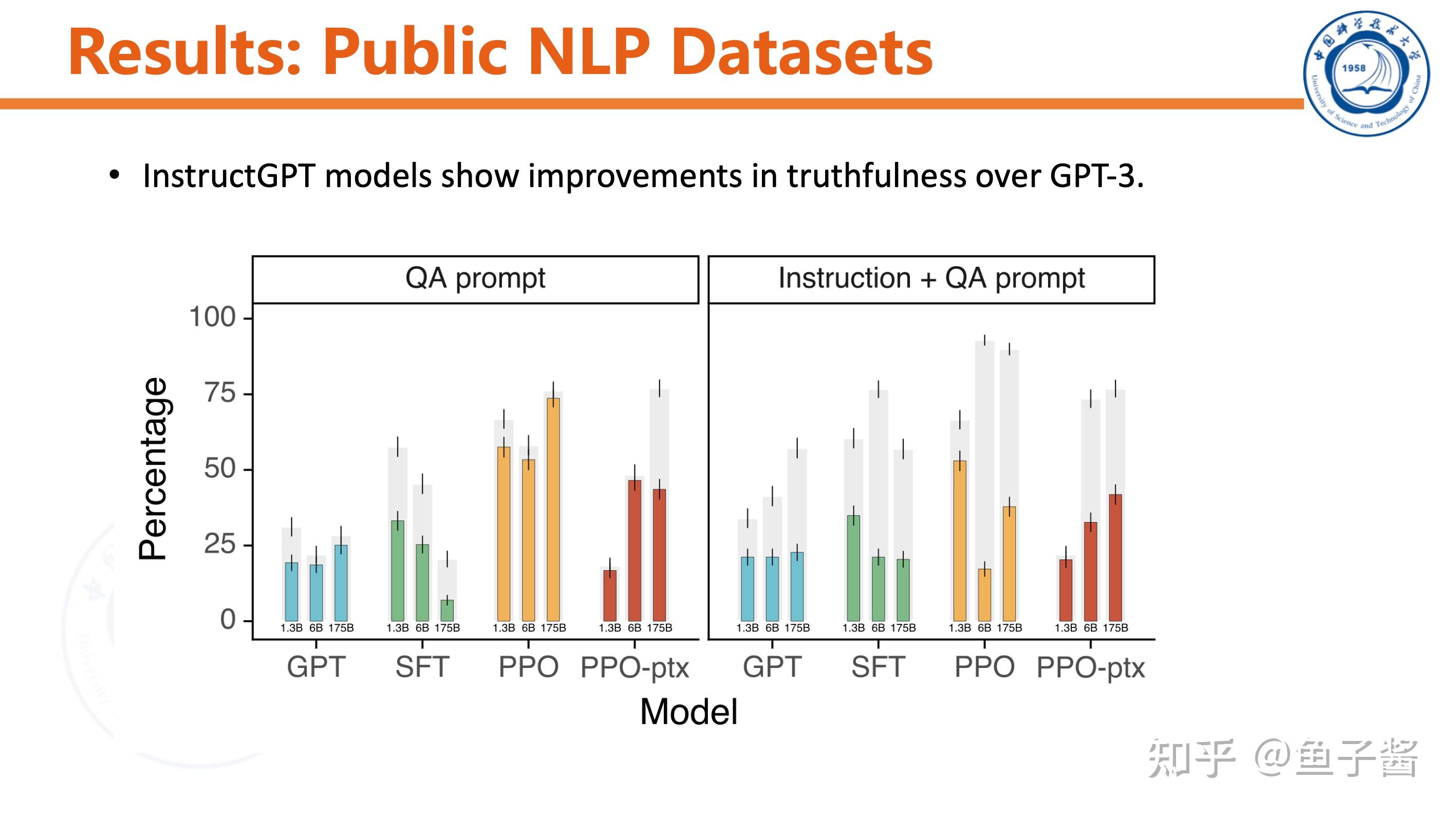





Discussion



写在结尾:DeepMind的工作总让人觉得很smart/novel,而OpenAI的工作总让人觉得很有用(sometimes很粗暴,有点“大力出奇迹”的意思)。读这两个机构的paper总是赏心悦目。
参考
^Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A. and Schulman, J., 2022. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155. https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf^Reinforcement learning from human feedback(RLHF) https://huggingface.co/blog/rlhf声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



