
相信国内外一众大厂都在着手复刻chatgpt,可能有些大厂还会在instructGPT基础上加些别的花样,不过我主张原生复刻,不整那些花里胡哨的。
第一步:复刻GPT3
第一小步:找开源GPT3方案
国内严格复刻GPT-3方案并开放模型的主要是阿里达摩院,其于modelscope平台提供的finetune和推理接口,目前提供的版本如下:
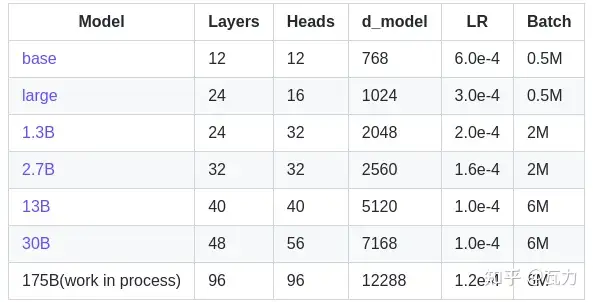
国外严格复刻GPT-3方案并开放模型的主要来自eleuther.ai,其于huggingface平台提供的finetune和推理接口,目前提供的版本如下:
另外facebook也对标gpt-3开放了opt模型,其于huggingface平台提供的finetune和推理接口,目前提供的版本如下:
模型OPT-125MOPT-350MOPT-1.3BOPT-2.7BOPT-6.7BOPT-13BOPT-30BOPT-66B第二小步:找合适的服务器资源
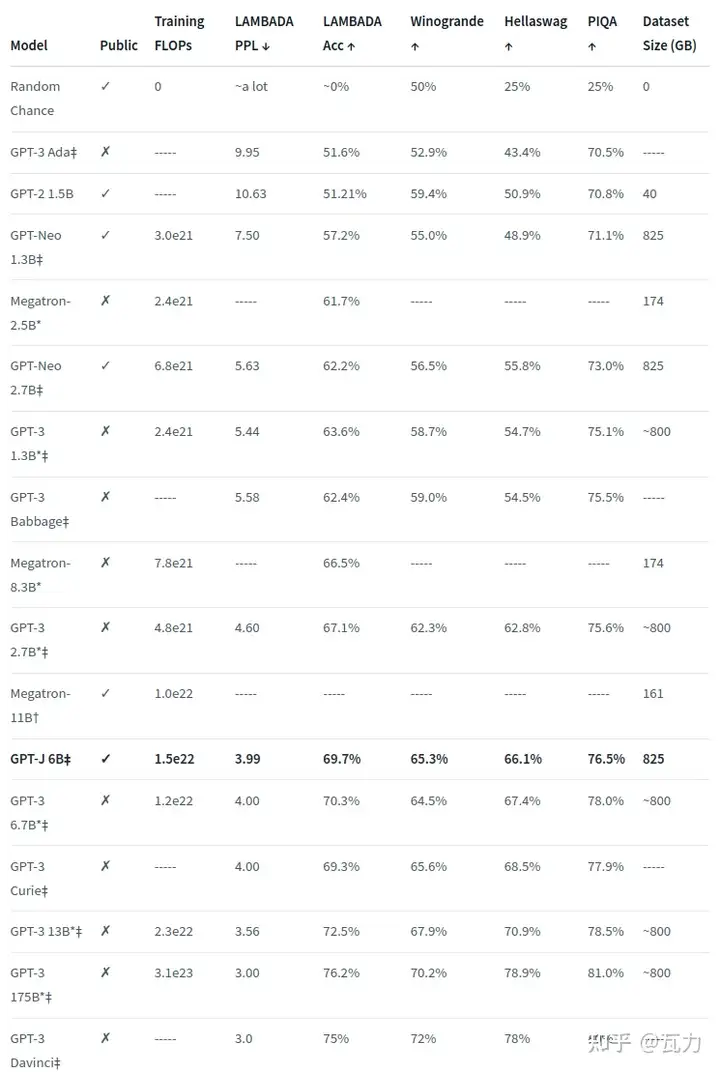
我们公司目前的gpu服务器顶配是3090(若干),目前本人找到的网上案例经过分布式并行计算以及模型加速后可以跑在3090的模型有GPT-J,本人预计公司的资源可以训练最多10B大小的模型,不过训练框架搭建过程中预计坑会比较多。
目前主流的大模型训练设备主要是英伟达的A100和V100,详情可参考我写的另外一篇大模型训练成本调研
第三小步:找合适的模型训练加速框架
目前LLMs普遍采用英伟达官方提供的Megatron-DeepSpeed组合方案,国内也有开源方案如Colossal-AI以及悟道开放的FastMoE等,这块儿有一定套路,但整体框架还挺复杂,需进一步调研,详情参见大模型训练加速框架预研。
第四小步:找合适的训练语料
参照达摩院开放阿里用到的数据源wiki和commoncrawl
另外此前悟道也开放200G的文本语料资源https://resource.wudaoai.cn/
第五小步:Finetune
准备工作到位,资源到位,准备finetune。
这里说明为什么是finetune,因为确实没必要从头训练,1个是资源耗不起,2是数据耗不起,网上开放的数据跟大厂真正训练用的数据不能比。
第二步:复刻InstructGPT
严格按照InstructGPT三个步骤来,别整其它花里胡哨。
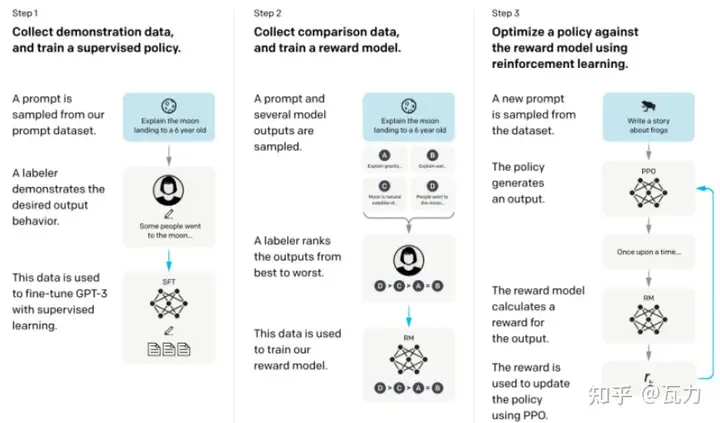
第一小步:Finetune
注意这里的finetune跟上面步骤的finetune稍有不同,上面那个用作语言生成任务为目标的调色板,这个是更进一步对话任务为目标的调色板。
这里严格参照官方提供的数据类型收集数据,这块的质量预期要比上面的更高。
第二小步:RM
首先搭建暗物智能InstructGPT-RM对话标注平台,这个平台用于对gpt-3生成的数据进行排序。
其次收集更高质量的prompt,这块儿可参考官方案例
然后训练RM模型
第三小步:PPO
这块儿最终用于优化gpt-3,预计工作量可能比较大,这块儿的开源代码参考https://github.com/lvwerra/trl.git
第三步:指标评测
这块儿可参考目前主流的评测方法,目前主要从一致性,相关性,信息性,吸引性,安全性等维度进行评测。
国外的就参考InstructGPT论文里介绍的评测方法,国内可参考PLATO,EVA,PANGU-BOT等。
指标评测非常重要,不能简单的对话几句就说这个模型好,那个模型不好,应当是全方位充分的评测。



