
2023年见证了AI人工智能技术的全面崛起,其中以ChatGPT、GPT-4、文心一言等AIGC大模型为代表,它们融汇了文本撰写、代码开发、诗词创作等多重功能,令人瞩目地展示了卓越的内容生产能力,给人们带来了深重的震撼。作为一名IT人士,AIGC大模型背后的通信技术,更要引起深入思考。没有优秀的网络,大模型训练就无从谈起。要构建大规模的训练模型集群,不仅需要GPU服务器、网卡等基础组件,网络搭建的问题更是亟待解决。究竟是怎样强大的网络在支撑着AIGC的运转?AI浪潮的全面来临又将对传统网络造成怎样的革命性变革?

前面提到的几个AIGC大模型,之所以那么厉害,不仅是因为它们背后有海量的数据投喂,也因为算法在不断进化升级。更重要的是,人类的算力规模,已经发展到了一定程度。强大的算力基础设施,完全能够支撑AIGC的计算需求。
在训练大型模型,由于模型的规模通常超出单个GPU的内存和计算能力,因此需要多个GPU来分担负载。在大模型训练过程中,有三种GPU负载分担的方式,分别是张量并行、流水线并行、数据并行。
1、数据并行 (Data Parallelism):
数据并行是一种简单直接的并行化技术,其中模型的完整副本被复制到多个处理器(如GPU)上。每个处理器或GPU都获得整个模型的一个副本,并在不同的数据子集上独立执行前向和反向传播。在每个训练步骤之后,所有处理器的模型权重更新需要被合并或同步,这通常通过某种形式的集合通信操作(如all-reduce)来完成。数据并行使得模型可以在更大的数据集上进行训练,因为数据被分割成多个小批次,分别在不同的处理器上处理。
想象一个大型的图书馆,你需要对所有书籍进行分类。数据并行就像是雇佣了多个图书管理员,每个人负责一部分书籍的分类工作。在模型训练的情况下,每个GPU拿到的是整个模型的一个副本,但是只处理整个数据集的一部分。所有GPU完成它们各自的任务后,会交换信息来同步更新模型权重。
2、张量并行 (Tensor Parallelism):
张量并行通常用于模型太大,无法容纳在单个处理器的内存中的情况。在这种并行化策略中,模型的不同部分(例如,神经网络层中的不同张量或参数组)被分配到不同的处理器上。这意味着每个处理器只负责计算模型的一部分。为了完成整个模型的前向和反向传播,处理器必须频繁交换它们的中间结果,这可能导致通信开销较大。张量并行要求处理器之间有高速的连接,以最小化这些交换的延迟。
如果数据并行是多个图书管理员各自处理一部分书籍,那么张量并行就像是每个图书管理员负责分类工作的一部分步骤。在模型训练中,每个GPU负责模型中的一部分计算,例如,一个GPU负责计算模型的前一半层,另一个GPU负责后一半。这样,模型的每一层可以跨多个GPU进行计算。
3、 流水线并行 (Pipeline Parallelism):
流水线并行是将模型的不同层或部分分配给不同的处理器,并以流水线的方式进行计算的并行化策略。在流水线并行中,输入数据被分成多个微批次(mini-batches),每个微批次依次通过模型的每一层。当一个微批次通过第一层计算后,它立刻被传递到下一层,而第一层则开始处理下一个微批次。这种方式可以减少处理器的空闲时间,但需要仔细地管理流水线,以避免产生过大的(stalls),这种情况下某些处理器可能会因为等待依赖的计算结果而暂停工作。
流水线并行就像是工厂流水线上的工人,每个工人完成一个特定的任务,然后将半成品传递给下一个工人。在模型训练中,模型被分成几个部分,每个部分在不同的GPU上顺序执行。当一个GPU完成它的部分计算后,它会将中间结果传递给下一个GPU继续计算。
在实际部署中,网络的设计必须考虑到这些并行策略对带宽和延迟的需求,以确保模型训练的效率和效果。有时,这三种并行策略会结合使用来进一步优化训练过程。例如,一个大型模型可能会在多个GPU上使用数据并行来处理不同的数据子集,同时在每个GPU内部使用张量并行来处理模型的不同部分。

我们来看大模型训练对AI算力的需求。伴随大模型的不断升级,模型训练对算力需求也不断增加,约每过3个月就会翻一倍。GPT-3模型(1750亿参数、45TB训练语料、消耗算力3640PFlops/s-Days),ChatGPT3,采用128台A100服务器,共计1024个A100卡训练,这样单服务器节点需要4个100G网络通道;而ChatGPT4、ChatGPT5等其它大模型,对于网络的需求会更高。
AIGC发展到现在,训练模型参数从千亿级飙升到了万亿级。为了完成这么大规模的训练,底层支撑的GPU数量,也达到了万卡级别规模。
那么问题来了,影响GPU利用率的最大因素,是什么呢?
答案是:网络。
一万甚至几万块的GPU,作为计算集群,与存储集群进行数据交互,需要极大的带宽。此外,GPU集群进行训练计算时,都不是独立的,而是混合并行。GPU之间,有大量的数据交换,也需要极大的带宽。
如果网络不给力,数据传输慢,GPU就要等待数据,导致利用率下降。利用率下降,训练时间就会增加,成本也会增加,用户体验会变差。
业界曾经做过一个模型,计算出网络带宽吞吐能力、通信时延与GPU利用率之间的关系,如下图所示: 大家可以看到,网络吞吐能力越强,GPU利用率越高;通信动态时延越大,GPU利用率越低。一句话,没有好网络,别玩大模型。
大家可以看到,网络吞吐能力越强,GPU利用率越高;通信动态时延越大,GPU利用率越低。一句话,没有好网络,别玩大模型。
怎样的网络,才能支撑AIGC的运行?
为了应对AI集群计算对网络的高要求,业界已经提出了多种解决方案。传统策略中,我们常见的有Infiniband、RDMA以及框式交换机这三种技术。
1. Infiniband组网
对于熟悉数据通信的专业人士而言,Infiniband组网并不陌生。它被誉为组建高性能网络的最佳途径,确保极高的带宽、无拥塞和低时延。事实上,ChatGPT和GPT-4所使用的网络便是Infiniband组网。然而,这种技术的缺点是成本高昂,相较于传统以太网组网,其花费要高出数倍。此外,这项技术相对封闭,目前业内成熟的供应商只有一家,使得用户在选择上受限。

2. RDMA网络
RDMA,即Remote Direct Memory Access,为一种新型的通信机制。在RDMA方案中,数据可以直接与网卡进行通信,绕过了CPU和复杂的操作系统,这不仅大幅提高了吞吐能力,也确保了更低的时延。
早些时候,RDMA主要承载在InfiniBand网络中。现在,它已经被逐渐移植到了以太网上。当前的主流组网方案是基于RoCE v2协议来构建支持RDMA的网络。不过,这种方案中的PFC和ECN技术,虽然是为了避免链路拥塞而产生的,但频繁触发可能会导致发送端暂停或降速,从而影响通信带宽。

3. 框式交换机
部分国外的互联网公司曾寄希望于框式交换机来满足高性能网络的需求。但这种方案存在扩展能力不足、设备功耗大以及故障域大等挑战,因此它只适用于小规模的AI计算集群部署。
新一代AIGC网络:DDC技术
鉴于传统方案存在的种种限制,一种全新的解决方案——DDC(Distributed Disaggregated Chassis)应运而生。DDC将传统的框式交换机进行“分拆”,增强了其扩展能力,并根据AI集群的大小灵活设计组网规模。通过这种创新方式,DDC克服了传统方案的局限性,为AI计算提供了一个更为高效、灵活的网络架构。

从规模和带宽吞吐的角度来看,DDC已经充分满足了AI大模型训练对于网络的需求。但网络运作并不只涉及这两个方面,它还需要在时延、负载均衡性、管理效率等方面进行优化。为此,DDC采取了以下技术策略:
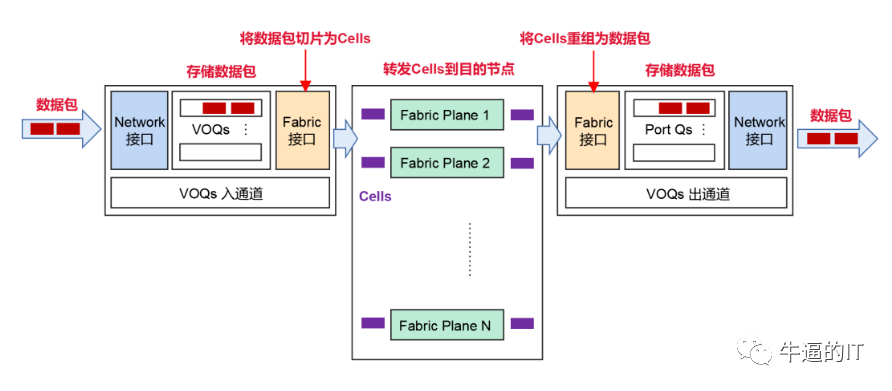
1. 基于VOQ+Cell的转发机制,有效对抗丢包
当网络遭遇突发流量,可能会导致接收端处理不及时,进而引发拥塞和丢包。DDC采用的基于VOQ+Cell的转发机制能够很好地解决这个问题。具体流程如下:
发送端在接收到数据包后,会先将其分类存储到VOQ中。在数据包发送前,NCP会先行发送Credit报文,以确认接收端是否有足够的缓存空间。只有在接收端确认有处理能力时,数据包才会被切片成Cells并动态负载均衡到Fabric节点。如果接收端暂时无法处理,数据包会在发送端的VOQ中暂存,并不直接转发。
这种机制充分利用了缓存,能够大幅度减少甚至避免丢包现象,从而提高整体通信稳定性,降低时延,并提升带宽利用率和业务吞吐效率。
2. PFC单跳部署,彻底避免死锁
PFC技术在RDMA无损网络中用于流量控制,它能够为以太网链路创建多个虚拟通道,并为每个通道设定优先级。但是,PFC也存在死锁问题。
在DDC组网下,由于所有NCP和NCF被看作一个整体设备,因此不存在多级交换机,从而彻底避免了PFC的死锁问题。


3. 分布式OS,增强可靠性
在DDC架构中,管理功能由NCC集中控制,但这样做可能存在单点故障的风险。为了避免这一问题,DDC采用了分布式OS,使每台NCP和NCF都能够独立管理,并拥有独立的控制面和管理面。这不仅大大提高了系统的可靠性,而且更方便部署。
结论:DDC通过其独特的技术策略,不仅满足了大规模AI模型训练的网络需求,还在多个细节方面进行了优化,确保网络在各种复杂条件下都能稳定、高效地运行。



