
1. tensor parallelism 概述
在之前的文章

中讨论过数据并行、模型并行和张量并行的原理和特点,感兴趣的可以回看一下。本章主要讨论 Tensor parallelism(TP) 及其应用。
Tensor parallelism is a type of model parallelism in which specific model weights, gradients, and optimizer states are split across devices.
简而言之就是把一个变量分散到多个设备并共同完成某个或多个计算操作。对于单个 Tensor/Op 很大 或者模型很大(如GPT3, chatGPT等)的情况,Tensor parallelism 的重要性非常明显。

实现 Tensor parallelism 的前提是计算设备需要处于互联状态,如上图所示,以GPU为例,因产品形态不同,有全连接和部分连接两种状态。
2. GPT 的 tensor parallelism 方案
下图是一个典型GPT模型的结构,主要包括:Embeddings, Decoder(n layers, self-attention+MLP), language model(LM)。下面将逐个部分讨论 tensor parallelism 的实现细节。

2.1 Embeddings 的并行
Embeddings 的难点在于weight较大,需要拆分到多个设备上,并实现正确的lookup,下面以4张卡简述其实现步骤:
将 wte 较均等分布到多张卡上将 input_ids 复制到所有卡上在每一张卡上input_ids分别lookup 卡上的子wte将所有卡上的值 all-reduce
2.2 Self-attention 的并行
Decoder 采用多头(mulit-head) self-attention,其算法如下:

由于有多个头,可以考虑使用head的某个因子数(n)作为设备数,每张卡跑 head//nhead//n 个头,那么问题就变成了如何拆分weight以及同步最终结果。
首先是weights的拆分,包括QKV的weight和线性输出层的weight,仍以4张卡为例,可按如下方式拆分:
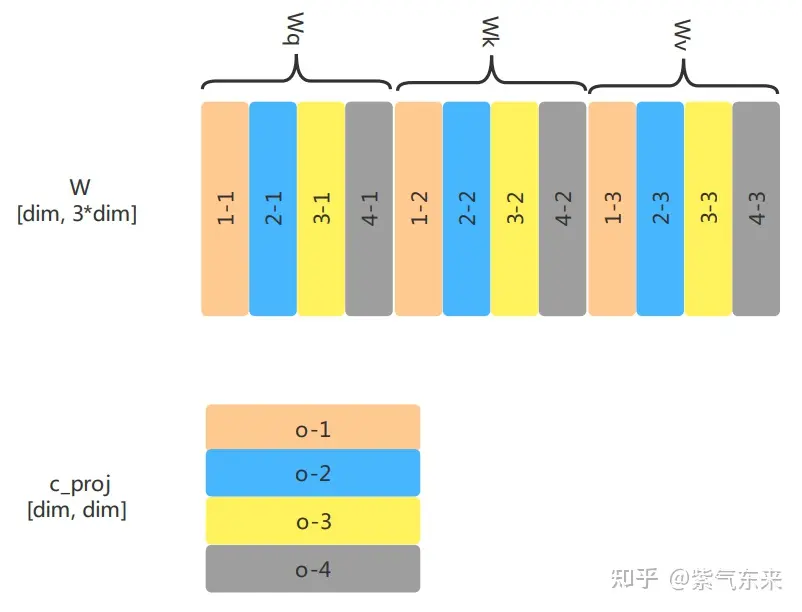
下面以4头4卡为例,展示其计算过程:

2.3 MLP 的并行
MLP 是线性操作,根据简单的矩阵分块计算原则,有
XWΩ=X[W1W2W3W4][Ω1Ω2Ω3Ω4]=XW1Ω1+XW2Ω2+XW3Ω3+XW4Ω4=XWΩX W \Omega=X\left[\begin{array}{llll} W_1 & W_2 & W_3 & W_4 \end{array}\right]\left[\begin{array}{l} \Omega_1 \\ \Omega_2 \\ \Omega_3 \\ \Omega_4 \end{array}\right]=X W_1 \Omega_1+X W_2 \Omega_2+X W_3 \Omega_3+X W_4 \Omega_4=X W \Omega
其中 XX 表示输入, W,ΩW, \Omega 表示2层的weight, 1,2,3,41,2,3,4 表示不同的设备号。
2.4 LM-head 的并行
LM-head 的主要部分就是一个matmul,即 [bs*seq_len, dim] * [dim, vocab] -> [bs*seq_len, vocab],由于这里和embeddings部分共用wte,因此可以按照如下方式计算得到:

需要注意的是,这里最后的collective 采用的是 all-gather 而非之前的 all-reduce。
2.5 CrossEntropyLoss 的并行
前边讨论的主要是推理过程中的并行过程,如果在训练过程中还需要考虑loss的并行,为此笔者曾专门进行过详细讨论,有兴趣可参考下文,本文在此不予赘述。

参考资料
[1]. 2110.14883.pdf (arxiv.org)
平生个里愿杯深,去国十年老尽少年心。 ——黄庭坚


