
推荐关注顶级架构师后台回复 1024 有特别礼包作者:然燃来源:juejin.cn/post/7268530145208451124
上一篇:软考证书,彻底爆了!!
大家好,我是顶级架构师。
最近遇到了文件预览的需求,但一搜索发现,这还不是一个简单的功能。于是又去查询了很多资料,调研了一些方案,也踩了好多坑。最后总结方案如下
花钱解决(使用市面上现有的文件预览服务)
微软google阿里云 IMMXDOCOffice Web 365wps开放平台前端方案
pptx的预览方案pdf的预览方案docx的预览方案xlsx(excel)的预览方案前端预览方案总结服务端方案
openOfficekkFileViewonlyOffice如果有其他人也遇到了同样的问题,有了这篇文章,希望能更方便的解决。
基本涵盖了所有解决方案。因此,标题写上 最全 的文件预览方案调研总结,应该不为过吧。
1市面上现有的文件预览服务
1.微软
docx,pptx,xlsx可以说是office三件套,那自然得看一下 微软官方 提供的文件预览服务。使用方法特别简单,只需要将文件链接,拼接到参数后面即可。
记得encodeURL
https://view.officeapps.live.com/op/view.aspx?src=${encodeURIComponent(url)}(1).PPTX预览效果:
优点:还原度很高,功能很丰富,可以选择翻页,甚至支持点击播放动画。
缺点:不知道是不是墙的原因,加载稍慢。
(2).Excel预览效果: (3).Doxc预览效果
(3).Doxc预览效果 (4).PDF预览效果
(4).PDF预览效果这个我测试没有成功,返回了一个错误,其他人可以试试。
 (5).总的来说
(5).总的来说对于docx,pptx,xlsx都有较好的支持,pdf不行。
还有一个坑点是:这个服务是否稳定,有什么限制,是否收费,都查不到一个定论。在office官方网站上甚至找不到介绍这个东西的地方。
目前只能找到一个Q&A:answers.microsoft.com/en-us/msoff…[1]
微软官方人员回答表示:

翻译翻译,就是:几乎永久使用,没有收费计划,不会存储预览的文件数据,限制文件10MB,建议用于 查看互联网上公开的文件。
但经过某些用户测试发现:
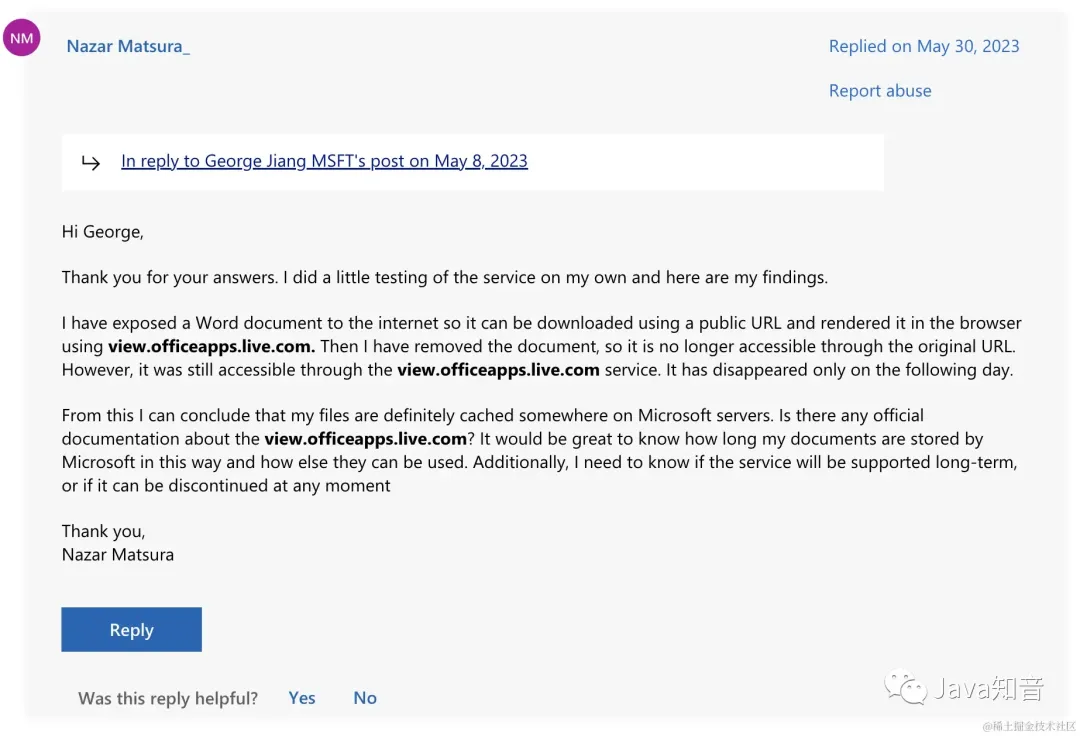
使用了微软的文件预览服务,然后删除了文件地址,仍然可访问,但过一段时间会失效。
2.Google Drive 查看器
接入简单,同 Office Web Viewer,只需要把 src 改为https://drive.google.com/viewer?url=${encodeURIComponent(url)}即可。
限制25MB,支持以下格式:

测试效果,支持docx,pptx,xlsx,pdf预览,但pptx预览的效果不如微软,没有动画效果,样式有小部分会错乱。
由于某些众所周知的原因,不可用
3.阿里云 IMM
官方文档如下:help.aliyun.com/document_de…[2]

付费使用
4.XDOC 文档预览
说了一些大厂的,在介绍一些其他的,需要自行分辨
官网地址:view.xdocin.com/view-xdocin…[3]

5.Office Web 365
需要注意的是,虽然名字很像office,但我们看网页的Copyright可以发现,其实是一个西安的公司,不是微软。
但毕竟也提供了文件预览的服务
官网地址:www.officeweb365.com/[4]

6.WPS开放平台
官方地址:solution.wps.cn/[5]

付费使用,价格如下:

2前端处理方案
1.pptx的预览方案
先查一下有没有现成的轮子,目前pptx的开源预览方案能找到的只有这个:github.com/g21589/PPTX…[6] 。但已经六七年没有更新,也没有维护,笔者使用的时候发现有很多兼容性问题。






简单来说就是,没有。对于这种情况,我们可以自行解析,主要步骤如下:
查询pptx的国际标准
解析pptx文件
渲染成html或者canvas进行展示
我们先去找一下pptx的国际标准,官方地址:officeopenxml[7]
先解释下什么是officeopenxml:
Office OpenXML,也称为OpenXML或OOXML,是一种基于XML的办公文档格式,包括文字处理文档、电子表格、演示文稿以及图表、图表、形状和其他图形材料。该规范由微软开发,并于2006年被ECMA国际采用为ECMA-376。第二个版本于2008年12月发布,第三个版本于2011年6月发布。该规范已被ISO和IEC采用为ISO/IEC 29500。
虽然Microsoft继续支持较旧的二进制格式(.doc、.xls和.ppt),但OOXML现在是所有Microsoft Office文档(.docx、.xlsx和.pptx)的默认格式。
由此可见,Office OpenXML由微软开发,目前已经是国际标准。接下来我们看一下pptx里面有哪些内容,具体可以看pptx的官方标准:officeopenxml-pptx[8]
PresentationML或.pptx文件是一个zip文件,其中包含许多“部分”(通常是UTF-8或UTF-16编码)或XML文件。该包还可能包含其他媒体文件,例如图像。该结构根据 OOXML 标准 ECMA-376 第 2 部分中概述的开放打包约定进行组织。

根据国际标准,我们知道,pptx文件本质就是一个zip文件,其中包含许多部分:
部件的数量和类型将根据演示文稿中的内容而有所不同,但始终会有一个 [Content_Types].xml、一个或多个关系 (.rels) 部件和一个演示文稿部件(演示文稿.xml),它位于 ppt 文件夹中,用于Microsoft Powerpoint 文件。通常,还将至少有一个幻灯片部件,以及一张母版幻灯片和一张版式幻灯片,从中形成幻灯片。
那么js如何读取zip呢?
找到一个工具: www.npmjs.com/package/jsz…[9]
于是我们可以开始尝试解析pptx了。
import JSZip from jszip// 加载pptx数据constzip = await JSZip.loadAsync(pptxData)
解析[Content_Types].xml每个pptx必然会有一个 [Content_Types].xml。此文件包含包中部件的所有内容类型的列表。每个部件及其类型都必须列在 [Content_Types].xml 中。通过它里面的内容,可以解析其他的文件数据
const filesInfo = awaitgetContentTypes(zip)
async function getContentTypes(zip: JSZip){
const ContentTypesJson = await readXmlFile(zip, [Content_Types].xml)
const subObj = ContentTypesJson[Types][Override]
constslidesLocArray = []
constslideLayoutsLocArray = []
for (let i = 0; i < subObj.length; i++) {
switch (subObj[i][attrs][ContentType]) {
case application/vnd.openxmlformats-officedocument.presentationml.slide+xml:
slidesLocArray.push(subObj[i][attrs][PartName].substr(1))
break case application/vnd.openxmlformats-officedocument.presentationml.slideLayout+xml:
slideLayoutsLocArray.push(subObj[i][attrs][PartName].substr(1))
break default:
}
}
return{
slides: slidesLocArray,
slideLayouts: slideLayoutsLocArray,
}
}
解析演示文稿先获取ppt目录下的presentation.xml演示文稿的大小
由于演示文稿是xml格式,要真正的读取内容需要执行 readXmlFile
const slideSize = awaitgetSlideSize(zip)
async function getSlideSize(zip: JSZip){
const content = await readXmlFile(zip, ppt/presentation.xml)
const sldSzAttrs = content[p:presentation][p:sldSz][attrs]
return{
width: (parseInt(sldSzAttrs[cx]) * 96) / 914400,
height: (parseInt(sldSzAttrs[cy]) * 96) / 914400,
}
}
加载主题根据 officeopenxml的标准解释
每个包都包含一个关系部件,用于定义其他部件之间的关系以及与包外部资源的关系。这样可以将关系与内容分开,并且可以轻松地更改关系,而无需更改引用目标的源。
除了包的关系部分之外,作为一个或多个关系源的每个部件都有自己的关系部分。每个这样的关系部件都可以在部件的_rels子文件夹中找到,并通过在部件名称后附加“.rels”来命名。
其中主题的相关信息就在ppt/_rels/presentation.xml.rels中
async function loadTheme(zip: JSZip){
const preResContent = awaitreadXmlFile(
zip,
ppt/_rels/presentation.xml.rels,
)
const relationshipArray = preResContent[Relationships][Relationship]
letthemeURI
if (relationshipArray.constructor=== Array) {
for (let i = 0; i < relationshipArray.length; i++) {
if(
relationshipArray[i][attrs][Type] ===
http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme) {
themeURI = relationshipArray[i][attrs][Target]
break}
}
} else if(
relationshipArray[attrs][Type] ===
http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme) {
themeURI = relationshipArray[attrs][Target]
}
if (themeURI === undefined) {
throw Error(“Cant open theme file.”)
}
return readXmlFile(zip, ppt/+ themeURI)
}
后续ppt里面的其他内容,都可以这么去解析。根据officeopenxml标准,可能包含:
 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
等等内容,我们根据标准一点点解析并渲染就好了。
完整源码:ranui[10]
使用文档:preview组件[11]
2.pdf的预览方案
(1).iframe和embedpdf比较特别,一般的浏览器默认支持预览pdf。因此,我们可以使用浏览器的能力:
<iframe src=“viewFileUrl”/>
但这样就完全依赖浏览器,对PDF的展示,交互,是否支持全看浏览器的能力,且不同的浏览器展示和交互往往不同,如果需要统一的话,最好还是尝试其他方案。
embed的解析方式也是一样,这里不举例子了
(2)pdfjs
npm: www.npmjs.com/package/pdf…[12]
github地址:github.com/mozilla/pdf…[13]
由mozilla出品,就是我们常见的MDN的老大。
而且目前 火狐浏览器 使用的 PDF 预览就是采用这个,我们可以用火狐浏览器打开pdf文件,查看浏览器使用的js就能发现
需要注意的是,最新版pdf.js限制了node版本,需要大于等于18
github链接:github.com/mozilla/pdf…[14]
如果你项目node版本小于这个情况,可能会无法使用。
具体使用情况如下:
完整源码:github.com/chaxus/ran/…[15]
使用文档:chaxus.github.io/ran/src/ran…[16]
import * as pdfjs from pdfjs-distimport * as pdfjsWorker from pdfjs-dist/build/pdf.work.entryinterfaceViewport {
width: number height: number viewBox: Array<number>
}
interfaceRenderContext {
canvasContext: CanvasRenderingContext2D | null transform: Array<number>
viewport: Viewport
}
interfacePDFPageProxy {
pageNumber: number getViewport: () =>Viewport
render: (options: RenderContext) => void}
interfacePDFDocumentProxy {
numPages: number getPage: (x: number) => Promise}
classPdfPreview {
private pdfDoc: PDFDocumentProxy | undefined pageNumber: number total: numberdom: HTMLElement
pdf: string | ArrayBuffer constructor(pdf: string | ArrayBuffer, dom: HTMLElement | undefined) {
this.pageNumber = 1 this.total = 0 this.pdfDoc = undefined this.pdf = pdf
this.dom = dom ? dom : document.body
}
private getPdfPage = (number: number) =>{
return new Promise((resolve, reject) =>{
if (this.pdfDoc) {
this.pdfDoc.getPage(number).then((page: PDFPageProxy) =>{
constviewport = page.getViewport()
const canvas = document.createElement(canvas)
this.dom.appendChild(canvas)
const context = canvas.getContext(2d)
const[_, __, width, height] = viewport.viewBox
canvas.width = width
canvas.height = height
viewport.width = width
viewport.height = height
canvas.style.width = Math.floor(viewport.width) + px canvas.style.height = Math.floor(viewport.height) + px constrenderContext = {
canvasContext: context,
viewport: viewport,
transform: [1, 0, 0, -1, 0, viewport.height],
}
page.render(renderContext)
resolve({ success: true, data: page })
})
} else{
reject({ success: false, data: null, message: pdfDoc is undefined})
}
})
}
pdfPreview = () =>{
window.pdfjsLib.GlobalWorkerOptions.workerSrc = pdfjsWorker
window.pdfjsLib
.getDocument(this.pdf)
.promise.then(async(doc: PDFDocumentProxy) => {
this.pdfDoc = doc
this.total = doc.numPages
for (let i = 1; i <= this.total; i++) {
await this.getPdfPage(i)
}
})
}
prevPage = () =>{
if (this.pageNumber > 1) {
this.pageNumber -= 1 } else{
this.pageNumber = 1}
this.getPdfPage(this.pageNumber)
}
nextPage = () =>{
if (this.pageNumber < this.total) {
this.pageNumber += 1 } else{
this.pageNumber = this.total
}
this.getPdfPage(this.pageNumber)
}
}
const createReader = (file: File): Promise<string | ArrayBuffer | null> => {
return new Promise((resolve, reject) =>{
const reader = newFileReader()
reader.readAsDataURL(file)
reader.onload = () =>{
resolve(reader.result)
}
reader.onerror = (error) =>{
reject(error)
}
reader.onabort = (abort) =>{
reject(abort)
}
})
}
export const renderPdf = async(
file: File,
dom?: HTMLElement,
): Promise<void> => {
try{
if (typeof window !== undefined) {
const pdf = awaitcreateReader(file)
if(pdf) {
const PDF = newPdfPreview(pdf, dom)
PDF.pdfPreview()
}
}
} catch(error) {
console.log(renderPdf, error)
}
}
3.docx的预览方案
我们可以去查看docx的国际标准,去解析文件格式,渲染成html和canvas,不过比较好的是,已经有人这么做了,还开源了
npm地址:www.npmjs.com/package/doc…[17]
使用方法如下:
import { renderAsync } from docx-previewinterfaceDocxOptions {
bodyContainer?: HTMLElement | nullstyleContainer?: HTMLElement
buffer: Blob
docxOptions?: Partial<Record<string, string | boolean>>
}
export const renderDocx = (options: DocxOptions): Promise<void> | undefined =>{
if (typeof window !== undefined) {
const{ bodyContainer, styleContainer, buffer, docxOptions = {} } = options
constdefaultOptions = {
className: docx,
ignoreLastRenderedPageBreak: false,
}
const configuration = Object.assign({}, defaultOptions, docxOptions)
if(bodyContainer) {
returnrenderAsync(buffer, bodyContainer, styleContainer, configuration)
} else{
const contain = document.createElement(div)
document.body.appendChild(contain)
returnrenderAsync(buffer, contain, styleContainer, configuration)
}
}
}
4.xlsx的预览方案
我们可以使用这个:
npm地址:www.npmjs.com/package/@vu…[18]
支持vue2和vue3,也有js的版本
对于xlsx的预览方案,这个是找到最好用的了。
5.前端预览方案总结
我们对以上找到的优秀的解决方案,进行改进和总结,并封装成一个web components组件:preview组件[19]
为什么是web components组件?
因为它跟框架无关,可以在任何框架中使用,且使用起来跟原生的div标签一样方便。
并编写使用文档: preview组件文档[20], 文档支持交互体验。
源码公开,MIT协议。
目前docx,pdf,xlsx预览基本可以了,都是最好的方案。pptx预览效果不太好,因为需要自行解析。不过源码完全公开,需要的可以提issue,pr或者干脆自取或修改,源码地址:github.com/chaxus/ran/…[21]
3服务端预览方案
1.openOffice
由于浏览器不能直接打开docx,pptx,xlsx等格式文件,但可以直接打开pdf和图片.因此,我们可以换一个思路,用服务端去转换下文件的格式,转换成浏览器能识别的格式,然后再让浏览器打开,这不就OK了吗,甚至不需要前端处理了。
我们可以借助openOffice的能力,先介绍一下openOffice:
Apache OpenOffice是领先的开源办公软件套件,用于文字处理,电子表格,演示文稿,图形,数据库等。它有多种语言版本,适用于所有常用计算机。它以国际开放标准格式存储您的所有数据,还可以从其他常见的办公软件包中读取和写入文件。它可以出于任何目的完全免费下载和使用。
官网如下:www.openoffice.org/[22]
需要先下载opneOffice,找到bin目录,进行设置
configuration.setOfficeHome(“这里的路径一般为C:\\Program Files (x86)\\OpenOffice 4”);
测试下转换的文件路径
public static void main(String[] args){
convertToPDF(“/Users/Desktop/asdf.docx”, “/Users/Desktop/adsf.pdf”);
}
完整如下:
packageorg.example;
importorg.artofsolving.jodconverter.OfficeDocumentConverter;
importorg.artofsolving.jodconverter.office.DefaultOfficeManagerConfiguration;
importorg.artofsolving.jodconverter.office.OfficeManager;
importjava.io.File;
public class OfficeUtil{
private staticOfficeManager officeManager;
private static int port[] = {8100};
/**
* start openOffice service.
*/ public static void startService(){
DefaultOfficeManagerConfiguration configuration = newDefaultOfficeManagerConfiguration();
try{
System.out.println(“准备启动office转换服务….”);
configuration.setOfficeHome(“这里的路径一般为C:\\Program Files (x86)\\OpenOffice 4”);
configuration.setPortNumbers(port); // 设置转换端口,默认为8100 configuration.setTaskExecutionTimeout(1000 * 60 * 30L);// 设置任务执行超时为30分钟 configuration.setTaskQueueTimeout(1000 * 60 * 60 * 24L);// 设置任务队列超时为24小时officeManager = configuration.buildOfficeManager();
officeManager.start(); // 启动服务 System.out.println(“office转换服务启动成功!”);
} catch(Exception e) {
System.out.println(“office转换服务启动失败!详细信息:”+ e);
}
}
/**
* stop openOffice service.
*/ public static void stopService(){
System.out.println(“准备关闭office转换服务….”);
if (officeManager != null) {
officeManager.stop();
}
System.out.println(“office转换服务关闭成功!”);
}
public static void convertToPDF(String inputFile, String outputFile){
startService();
System.out.println(“进行文档转换转换:” + inputFile + ” –> “+ outputFile);
OfficeDocumentConverter converter = newOfficeDocumentConverter(officeManager);
converter.convert(new File(inputFile), newFile(outputFile));
stopService();
}
public static void main(String[] args){
convertToPDF(“/Users/koolearn/Desktop/asdf.docx”, “/Users/koolearn/Desktop/adsf.pdf”);
}
}
2.kkFileView
github地址:github.com/kekingcn/kk…[23]
支持的文件预览格式非常丰富
接下来是 从零到一 的启动步骤,按着步骤来,任何人都能搞定
安装java:brew install java
安装maven,java的包管理工具:brew install mvn
检查是否安装成功执行java –version和mvn -v。我这里遇到mvn找不到java home的报错。解决方式如下:
我用的是zsh,所以需要去.zshrc添加路径:
exportJAVA_HOME=$(/usr/libexec/java_home)
添加完后,执行
source.zshrc
安装下libreoffice :kkFileView明确要求的额外依赖,否则无法启动
brew install libreoffice
mvn安装依赖进入项目,在根目录执行依赖安装,同时清理缓存,跳过单测(遇到了单测报错的问题)
mvn clean install -DskipTests
启动项目找到主文件,主函数mian,点击vscode上面的Run即可执行,路径如下图
访问页面启动完成后,点击终端输出的地址
最终结果最终展示如下,可以添加链接进行预览,也可以选择本地文件进行预览
预览效果非常好
3.onlyOffice
官网地址:www.onlyoffice.com/zh[24]
github地址:github.com/ONLYOFFICE[25]
开发者版本和社区版免费,企业版付费:www.onlyoffice.com/zh/docs-ent…[26]
预览的文件种类没有kkFileView多,但对office三件套有很好的支持,甚至支持多人编辑。
4总结
外部服务,推荐微软的view.officeapps.live.com/op/view.aspx,但只建议预览一些互联网公开的文件,不建议使用在要求保密性和稳定性的文件。
对保密性和稳定性有要求,且不差钱的,可以试试大厂服务,阿里云解决方案。
服务端技术比较给力的,使用服务端预览方案。目前最好最全的效果是服务端预览方案。
不想花钱,没有服务器的,使用前端预览方案,客户端渲染零成本。
5参考文档:
在java中如何使用openOffice进行格式转换[27]
MAC搭建OpenOffice完整教程-保姆级[28]
纯js实现docx、xlsx、pdf文件预览库,使用超简单[29]
前端实现word、excel、pdf、ppt、mp4、图片、文本等文件的预览[30]
参考资料
[1]answers.microsoft.com/en-us/msoff…: https://answers.microsoft.com/en-us/msoffice/forum/all/what-is-the-status-of-viewofficeappslivecom/830fd75c-9b47-43f9-89c9-4303703fd7f6
[2]help.aliyun.com/document_de…: https://help.aliyun.com/document_detail/63273.html
[3]view.xdocin.com/view-xdocin…: https://view.xdocin.com/view-xdocin-com_6x5f4x.htm
[4]www.officeweb365.com/: https://www.officeweb365.com/
[5]solution.wps.cn/: https://solution.wps.cn/
[6]github.com/g21589/PPTX…: https://github.com/g21589/PPTX2HTML
[7]officeopenxml: http://officeopenxml.com/
[8]officeopenxml-pptx: http://officeopenxml.com/anatomyofOOXML-pptx.php
[9]www.npmjs.com/package/jsz…: https://www.npmjs.com/package/jszip
[10]ranui: https://github.com/chaxus/ran/tree/main/packages/ranui
[11]preview组件: https://chaxus.github.io/ran/src/ranui/preview/
[12]www.npmjs.com/package/pdf…: https://www.npmjs.com/package/pdfjs-dist
[13]github.com/mozilla/pdf…: https://github.com/mozilla/pdfjs-dist
[14]github.com/mozilla/pdf…: https://github.com/mozilla/pdf.js/blob/master/package.json
[15]github.com/chaxus/ran/…: https://github.com/chaxus/ran/tree/main/packages/ranui
[16]chaxus.github.io/ran/src/ran…: https://chaxus.github.io/ran/src/ranui/preview/
[17]www.npmjs.com/package/doc…: https://www.npmjs.com/package/docx-preview
[18]www.npmjs.com/package/@vu…: https://www.npmjs.com/package/@vue-office/excel
[19]preview组件: https://chaxus.github.io/ran/src/ranui/preview/
[20]preview组件文档: https://chaxus.github.io/ran/src/ranui/preview/
[21]github.com/chaxus/ran/…: https://github.com/chaxus/ran/tree/main/packages/ranui
[22]www.openoffice.org/: https://www.openoffice.org/
[23]github.com/kekingcn/kk…: https://github.com/kekingcn/kkFileView
[24]www.onlyoffice.com/zh: https://www.onlyoffice.com/zh
[25]github.com/ONLYOFFICE: https://github.com/ONLYOFFICE
[26]www.onlyoffice.com/zh/docs-ent…: https://www.onlyoffice.com/zh/docs-enterprise-prices.aspx
[27]在java中如何使用openOffice进行格式转换: https://blog.csdn.net/Li_Zhongxin/article/details/132105957
[28]MAC搭建OpenOffice完整教程-保姆级: https://blog.51cto.com/u_15899048/5902747
[29]纯js实现docx、xlsx、pdf文件预览库,使用超简单: https://juejin.cn/post/7251199685130059833
[30]前端实现word、excel、pdf、ppt、mp4、图片、文本等文件的预览: https://juejin.cn/post/7071598747519549454
欢迎大家进行观点的探讨和碰撞,各抒己见。如果你有疑问,也可以找我沟通和交流。扩展:接私活儿
为了跟上AI时代我干了一件事儿,我创建了一个知识星球社群:ChartGPT与副业。想带着大家一起探索ChatGPT和新的AI时代。
有很多小伙伴搞不定ChatGPT账号,于是我们决定,凡是这三天之内加入ChatPGT的小伙伴,我们直接送一个正常可用的永久ChatGPT独立账户。
不光是增长速度最快,我们的星球品质也绝对经得起考验,短短一个月时间,我们的课程团队发布了8个专栏、18个副业项目:
简单说下这个星球能给大家提供什么:
1、不断分享如何使用ChatGPT来完成各种任务,让你更高效地使用ChatGPT,以及副业思考、变现思路、创业案例、落地案例分享。
2、分享ChatGPT的使用方法、最新资讯、商业价值。
3、探讨未来关于ChatGPT的机遇,共同成长。
4、帮助大家解决ChatGPT遇到的问题。
5、提供一整年的售后服务,一起搞副业
星球福利:
1、加入星球4天后,就送ChatGPT独立账号。
2、邀请你加入ChatGPT会员交流群。
3、赠送一份完整的ChatGPT手册和66个ChatGPT副业赚钱手册。
其它福利还在筹划中… 不过,我给你大家保证,加入星球后,收获的价值会远远大于今天加入的门票费用 !
本星球第一期原价399,目前属于试运营,早鸟价139,每超过50人涨价10元,星球马上要来一波大的涨价,如果你还在犹豫,可能最后就要以更高价格加入了。。
早就是优势。建议大家尽早以便宜的价格加入!
最后给读者整理了一份BAT大厂面试真题,需要的可扫码回复“面试题”即可获取。
「顶级架构师」建立了读者架构师交流群,大家可以添加小编微信进行加群。欢迎有想法、乐于分享的朋友们一起交流学习。
扫描添加好友邀你进架构师群,加我时注明【姓名+公司+职位】
版权申明:内容来源网络,版权归原作者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
猜你还想看
牛逼啊!接私活必备的 N 个开源项目!赶快收藏吧(附源码合集第九期)!
再见Jenkins!一款更适合国人的自动化部署工具,贼带劲!!



